Self-improving agent in a complex environment
During my second Master’s degree in AI at Sorbonne University, I participated in a school project where we had to read a scientific article about AI methods used in robotics. Our task was to replicate the methods used in the article and compare our results with those presented in the paper. The article1 focused on using reinforcement learning methods, such as adaptive heuristic critique (AHC) learning architecture2 3 and Q-learning4, in a complex simulated environment. The simulated environment consisted of an agent, enemies, food, and obstacles, with the agent’s goal being to survive by using its sensors to avoid enemies and obstacles while collecting food.
To complete the project, we had to create the environment, the characters (agent and enemies), and the agent’s sensors using coarse coding5 and the Python GUI toolkit Tkinter. We also had to adjust the characters’ movements to be compatible with the Tkinter GUI. Once that was done, we implemented the Q-Learning method using a neural network to enable the agent to choose its movements autonomously, similar to the Deep-Q reinforcement learning models. The neural network had three layers: an input layer (145 neurons) that received input from the agent’s sensors, a hidden layer (30 neurons), and an output layer (1 neuron) corresponding to the Q-Value. Finally, we compared our results, represented by the learning curves, with those presented in the paper.
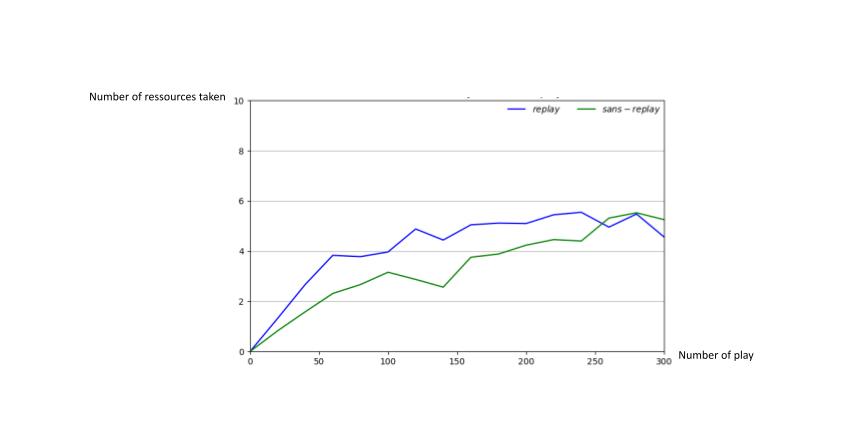
Figure - Learning curves showing the average number of resources eaten by the agent during 300 plays with and without using experience replay (blue and green curves, respectively).
The above learning curves show how well the agent performed during 300 training simulations. Over time, the agent learns to collect resources while avoiding enemy encounters. To help you understand how we built the simulation, we have included a short demo that demonstrates the agent’s performance.
-
Long-Ji Lin. 1992. Self-Improving Reactive Agents Based on Reinforcement Learning, Planning and Teaching. Mach. Learn. 8, 3–4 (May 1992), 293–321. ↩
-
Richard Stuart Sutton.Temporal Credit Assignment in Reinforcement Learning. PhD thesis, 1984. AAI8410337. ↩
-
Sutton, Richard & Barto, Andrew. (1990). Time-Derivative Models of Pavlovian Reinforcement. ↩
-
Watkins, C. J. C. H.. “Learning from Delayed Rewards.” PhD diss., King’s College, Oxford, 1989. ↩
-
D. E. Rumelhart, G. E. Hinton, and R. J. Williams. 1986. Learning internal representations by error propagation. Parallel distributed processing: explorations in the microstructure of cognition, vol. 1: foundations. MIT Press, Cambridge, MA, USA, 318–362. ↩